
- 간단한 자기소개
- 지원동기
- 장단점
- 나의 비전 : 사람들에게 긍정적인 영향을 줄 수 있는 사람이 되는 것.
- 프로젝트 하면서 어려움 극복 : bizkicks 얘기?
- 회사에 대해 궁금한 점
- 협업 방식
- 각 프로젝트
- 인성
개발지식
객체지향
정의
class vs instance
특징 4가지
장단점
객체들의 상호작용으로 프로그램을 구현하는 방법.
객체는 어떤 개념을 추상화하고 모델링한 요소. state와 behavior를 가짐.
- 추상화란 불필요한 정보는 숨기고 중요한 정보만을 보여주는 것(컴퓨터 과학)
class : 설계도, instance : class로 만들어진 메모리에 올라간 실체.
특징
abstraction : OOP에서 abstraction은 불필요한 정보는 private으로 숨기고 중요한 정보를 public으로 노출하고, 공통된 부분을 상위 class로 추출하는 것.
encapsulation : information hiding
inheritance : 공통 부분을 추출
polymorphism : static (overloading) - 이름만 같은 함수로 사용하는 방법, dynamic (overriding) - 부모 class method를 자식 class에서 재정의
장단점
코드 재사용률이 높아짐
단점으로는 객체들이 상호작용하기 때문에 느리다.
SOLID
5가지 + 각각의 예시
single responsibility principle
모든 class가 하나의 책임을 가짐, 변경의 이유가 하나뿐.
지키지 않으면 한 책임의 변경에 의해 다른 책임이 변경될 수 있음.
open closed principle
확장에는 열려 있고 수정에는 닫혀 있음. 코드 변화를 적게 하면서 기능 변화/확장할 수 있게.
확장 시 변경으로 인한 영향을 최소화하는 것이 목적.
예시로 분기문 : polymorphism이나 map을 사용해 적용 가능.
liskov substitution principle
subtype이 supertype으로 치환할 수 있음. supertype 자리에 subtype 넣어도 수행에는 변화가 없어야 한다.
parent class method의 동작 의도를 크게 수정하면 안되는 것이 목적.
예시 : 직사각형/정사각형. - 명확한 관계가 있을 때만 상속을 써야 함.
interface segregation principle
object는 자신이 사용하지 않는 method를 포함한 interface에 의존하면 안 된다.
사용하지 않는 method를 가진 interface에 의존하는 경우, 사용하지 않는 method가 변경되어도 재컴파일되어야 하기 때문.
dependency inversion principle
dependency를 가지는 경우, 구현체가 아니라 추상화에 의존해야 한다.
inversion인 이유는, 기존에는 상위 모듈이 하위 모듈에 의존하고 있었다. 그러나 interface를 사용하면서 하위 모듈이 상위 모듈(abstraction)에 의존하게 되었다. 때문에 inversion.
지키지 않는 경우, 요구사항 하나의 변화로 인해 dependency가 걸린 모든 것들을 다 바꾸어야 한다.
예시 : dependency injection (upcasting), abstract factory
디자인패턴
정의, 예시
template
strategy
abstract factory
factory
singleton
adapter
proxy
composite pattern
decorator pattern
facade
observer
소프트웨어 설계 시 많이 사용하는 구조들을 모아놓은 패턴.
내가 사용한 것들
template
customize한 부분과 invariant한 부분을 구분하는 방법. invariant는 abstract class에서 정의, customize는 concrete class 에서 정의. 객체에서 abstraction이고, 공통 부분만 빼내는 방식.
strategy
한 알고리즘의 여러 변형본이 필요할 때 사용하는 방법. 같은 것을 인자로 받는 if-else문을 분리하기 좋다.
예시로 내가 사용한 if-else를 변경한 것.
abstract factory
concrete class 없이 연관된 객체를 생성하는 방법
단점으로는 새로운 것을 넣기 힘들다는 것.
내가 사용한 부분은 auth client와, converter에서 authclient가 필요했다. 그러나 이를 explicit하게 생성하면 의존성이 드러난다. 때문에 이를 숨기고, auth client와 converter를 같이 생성하게 했다.
factory
class 생성자를 subclass에 맡김.
예시로는 attribute 값 할당을 subclass에서 해 줘야 할 때 사용.
singleton
단 하나의 instance만 사용하게 하는 방법. 메모리 낭비 방지.
private 생성자 + static 변수를 사용한다.
DB connection pool 등이 있다.
adapter
서로 호환되지 않는 interface를 작동시키는 패턴. target의 행동에 추가적인 로직을 처리해 기존 interface가 동작하게 하는 방식. 예시로는 n2t에서 네이버 형식을 티스토리 형식으로 바꾸기 위해 중간 자료구조를 하나 두고, 이를 사용한 방식이다. 직접적으로 class는 아니지만 . . .
proxy
실 연산을 다른 객체로 위임하는 패턴.
예시로실 객체를 생성하기 전 caching을 하거나 호출 시점에 만들 수 있다.
composite pattern
전체-부분 관계를 가질 때 object 관계를 정의. 내가 사용한 부분은 n2t scrapper에서 모든 type을 처리하기 위해 if-else를 변형한 strategy를 사용했는데, 이렇게 쓰니 sectionparser가 test module parsing + section parsing 2가지 역할을 가지게 되었다. 그러나 이런 tree 구조의 경우 composite pattern을 사용했으면 더 좋지 않았을까 싶다.
decorator pattern
composite와 유사. object를 dynamic하게 확장할 때 사용.
카페 음료수 예시
facade
복잡한 subsystem에 대한 interface를 만드는 방법
observer
하나의 object가 다른 여러 개의 object에게 영향을 끼칠 때 object끼리의 direct coupling 만드는 대신 observer를 두고, observer가 해당 object들에게 대신 전달하는 방식. 이를 통해 coupling 줄일 수 있음. ex) front에서 listener
Docker
개념 (container)
virtualize vs containerize
image
어떤 프로그램의 실행에 필요한 모든 파일을 포함한 패키지를 image라고 한다.
이 image를 실행한 것이 container.
vm은 운영체제까지 띄우는 방식
container는 코드, 실행 환경을 포함해 띄우는 방식.
가상화의 정도가 다름. vm은 hw까지 가상화하지만 container는 sw만 가상화함. 즉, container는 os를 공유.
vm은 host os 위에 hypervisor(os의 resource 관리해주는 도구)를 올리고, hypervisor가 각각의 os를 올림. hw를 가상화하기 때문에 각 os는 완전히 independent하지만 무겁다.
container는 host os 위에 docker engine이 올라가고, docker engine이 각각의 container를 관리함. host는 os는 공유하되, process들의 격리 환경을 만듬.
Kubernetes
개념
container application들의 deploy, scaling 등을 제공하는 관리 툴.
scaling은 CPU나 memory같은 자원 등등의 metric에 따라서 scaling한다. scaling은 pod 개수나 resource 할당량 등을 조절할 수 있다.
Git 전략
Git Flow
master, develop, feature, release, hotfix
master에서 develop 분기, develop에서 feature 분기.
develop에서 feature가 다 merge되었다면 qa를 위해 release 분기. 이후 버그 수정
최후에는 release를 develop과 main으로 merge.
hotfix는 main에서 나옴.
bizkicks의 경우 develop과 release를 하나로 합쳐 사용했다.
Github Flow
main은 항상 배포가 가능한 상태로 유지 / 최신 / stable을 유지해야 한다. 이외 feature가 있다.
merge 전에 테스트를 해야 한다.
gitlab
배포만을 담당하는 production branch를 하나 두고, pre-production (배포 전 테스트) branch를 하나 둔다.
정리
git flow와 github flow를 쓰면서 느낀 차이점은, develop branch가 있냐 없냐이다. git flow는 develop branch를 하나 두고 github flow는 그게 없다. git flow의 경우 develop branch에 변경사항이 생겼을 때 문제가 생기더라도 부담감이 덜하다. main이 아니기 때문에.. 그리고 release를 위해 별개의 branch를 생성하기 때문에 각 branch의 역할 분담이 확실하고, 오류가 났을 때도 대처가 편한 것 같다. 그러나 복잡도가 높아 PR이 많이 생성된다는 단점이 있다.
반면 github flow에서 merge를 할 때 충분한 테스트를 하지 않으면 main이 망가질 수 있다는 위험?부담이 좀 있는 것 같다. 그렇지만 훨씬 간단하기 때문에 작은 프로젝트에서 진행하기 좋을 것 같다.
MySQL, MariaDB
왜 사용했는지
어떤 특징이 있는지
왜 사용했는지
어떤 특징이 있는지
RDB에 대한 선택 이유 : 데이터가 정형화되어 있기 때문에 이해하기 쉽다. 비정형화되어 있는 NoSQL보다 이해하기가 더 쉽고, NoSQL을 사용할 만큼 트래픽이 많지 않을 거라 생각했기 때문에 RDB를 선택했다.
RDB에는 MySQL, PostgreSQL, Oracle 정도가 있다고 생각한다.
oracle은 과금을 해야 해서 선택지에서 아웃.
데이터를 자주 읽는 경우 mysql, 자주 쓰는 경우 postgres
- mysql : write lock을 사용해 concurrency 구현. 때문에 쓸 때 느림. 러닝커브가 낮음
- PostgreSQL : 객체 저장 가능(배열 등). write lock을 걸지 않고 mvcc를 사용함.
MariaDB는 MySQL에서 fork되어 나온 것. mariadb 사용한 이유는 mysql은 영리 목적으로 하면 라이센스 비용을 내야 하는 것으로 알고 있어서 해커톤 했을 때는 이거 나중에 채팅앱으로 만들자~ 해서 mariadb 사용하기로 했다. 어차피 둘 다 거의 유사한 db라서 그렇게 사용하기로 함.
격리 수준
- mysql : repeatable read
- oracle : read commited
- postgresql : read commited
MVC
model-controller-view
model : 데이터 저장
controller : model, view 변경
view : 사용자에게 보이는 부분
spring의 경우, model은 repository(db), controller는 controller, service, view는 jsp가 처리.
mvc1의 경우 jsp가 controller, view 둘 모두를 수행하고 있었다. 때문에 현대 spring은 mvc 2 model을 사용한다.
Async / Sync / Block / Non-Block
각각의 정의
sync 여부 : 작업이 동기화 되었는지 여부
sync : 작업이 동기화 된 방식. A가 B를 call했을 때 B의 결과가 A로 바로 들어가면 sync.
async : 작업이 동기화되지 않은 방식. A가 B를 call했을 때 A가 B의 결과를 요청해야 하면 async. async의 경우 대기 시간이 필요한 작업을 효율적으로 다룬다.
blocking 여부 : 제어권을 넘기는지 여부. 작업이 blocking되는지 여부라고 보면 된다
blocking : A가 B를 call했을 때 B가 자신의 작업이 끝나기 전까지 제어권을 넘겨주지 않는 방식. A의 작업이 block된다.
non-blocking : A가 B를 call했을 때 B가 제어권을 바로 넘겨주는 방식. A의 작업이 block되지 않는다.
Blockchain
블록체인은 안전하게 데이터를 저장하고, 운영할 수 있게 하는 P2P 네트워킹 기술이다. 누군가가 블록체인에 트랜잭션을 추가하려고 하면 이 요청은 네트워크에 전송되며, 공개 트랜잭션이 승인된 후에만 블록체인에 추가할 수 있다. 이를 통해 중앙 시스템 없이 모든 거래에 대해 모든 사용자들이 알 수 있는 P2P 네트워크가 구축된다.
1. 네트워크에 전파
2. 트랜잭션 검증 (잔고 충분한지, 서명 유효한지, 중복되지 않았는지)
3. 채굴 : 블록의 해시값이 해당 블록체인의 기준에 맞는 결과가 나올 때까지 해시값을 반복적으로 계산해 해당 조건이 만족하는 블록을 블록체인 끝에 추가하고 네트워크로 전송. (만약 2개 이상의 노드가 다른 결과값을 블록체인 결과가 분기되는데, 네트워크 과정에서 더 긴 체인을 사용함.)
- 채굴 : 해시값을 계산하기 위해 많은 시도가 필요하며, 때문에 공격자가 네트워크를 공격하기 위해 거대한 리소스를 사용해야 한다. 또한 채굴은 누구나 할 수 있기 때문에 탈중앙화를 꾀할 수도 있음. + 보상 시스템으로 유통도 처리함.
- 한편 해싱 결과를 찾기 때문에, 찾는 것은 어렵지만 검증은 매우 빠름.
체인 : 각 트랜잭션이 체인 형태로 엮여 있음. 좀 더 자세하게는, 이전 블록의 해시값을 현재 블록에 넣어 사용함. 때문에 이전 블록을 조작하는 경우 현재 블록의 해시값이 크게 바뀌게 됨.
아키텍처
아키텍처 간단히(pipelined CPU 동작 간단히) + 베릴로그 언어
HW가 lock을 어떻게 처리하는지
RISC-V
R(arithmetic), I(load), S(store), B(branch), J(jump)
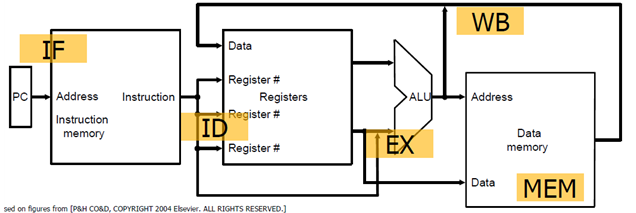
1) IF : instruction fetch
2) ID : instruction decode and operand fetch
3) EX : ALU/execute
4) MEM : memory access
5) WB : write-back
single-cycle CPU는 비효율성 때문에 사용하지 않는다. 모든 insturction이 가장 느린 instruction만큼 걸리기 때문이다.
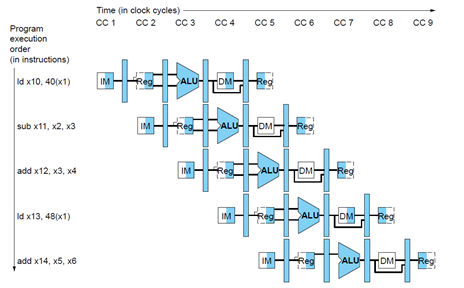
structure hazard : resource가 busy인 것. 여기서는 memory에 값을 쓸 때 + 읽을 때가 동시에 오는 경우 발생함. 이를 해결하기 위해 clock을 절반으로 나눠, 앞쪽 절반에서는 read, 뒤쪽 절반에서는 write 하는 식으로 함.
data hazard : 이전 instruction 실행 결과를 기다려야 하는 것. stall(실행 멈춤)하거나 forwarding(실행 결과를 앞단에 넣어줌)한다.
control hazard : 이전 instruction 실행 결과에 따라 다음 instruction이 결정되는 것. 예측을 통해 해결. +4(다음 instruction)을 수행하다가, 분기 결과에 따라 해당 instruction을 멈출지 결정.
.
hw의 lock 처리 방법
atomic instruction의 경우 hw가 중간에 다른 명령어를 실행시키지 않는 방식으로 구현함.
memory에 대한 접근이기에, memory bus에서 해당 memory address로 접근하는 요청에 대해 lock을 건다.
async 방식으로 프로그래밍을 하는 거의 첫 경험이라 개념 잡는 데도 많은 시간이 걸렸고, instruction 종류도 많아 구현하는 데 어려웠다. 이전에는 sequential programming 형식으로, 각 module의 연산 결과를 다른 module에서 바로바로 받아와 쓸 수 있었는데, 베릴로그는 모든 상태 변화가 clock 신호와 동기화되어 있기 때문에 기존 프로그래밍 패러다임과 차이가 있어서 어려웠다. 해결은 동기/비동기에 대한 개념을 명확하게 잡고, 결국 시간 많이 쓰니까 해결 되더라.
Async / Await
await는 promise에서 then을 쓰는 것과 동일하다.
즉.. promise의 값이 나올 때까지 await한다는 것.
let a = await func();을 통해 async func()의 promise 결과를 바로 받을 수 있다.
사실상 코드 이쁘게 만드는 방법. (더 직관적인 이해 가능)
오류 코드도 간편해지고 sync style이랑 코드가 비슷해짐. callback도 사용하지 않아도 됨. 여러 개의 promise도 사용할 수 있음.
javascript 동작 방식
asynchronous event loop model ?
event가 발생할 때마다 이를 처리하기 위한 함수를 등록하고, event 발생 시 해당 함수 실행하는 방식.
javascript는 single thread 기반의, event loop model.
내부적으로 call stack에다가 코드를 넣어서 동작시킨다. 만약 바로 실행할 수 없는 코드의 경우(timeout, event listener 등등), browser web API 내에 해당 코드들을 넣어 둔다. (일종의 대기실, 새로운 thread가 생성되어 작업을 함) 내부적으로 동작 과정에서 async하게 background thread를 사용한다.
- 즉, async 작업이 발생하면 해당 작업을 background thread pool로 보내 새로운 thread를 생성해 사용한다.
browser web API에서 작업이 끝나면 바로 call stack으로 들어가서 코드가 실행되는 게 아니라, callback queue로 들어간 이후에 하나씩 call stack으로 올려보낸다. (단, call stack이 빌 때만 올려준다. - 때문에 I/O가 많은 작업에 유리하며 CPU 작업이 많은 서버인 경우 불리하다.)
Node.js vs Spring
node.js
- asynchronous event loop model을 사용하므로, I/O 작업을 비동기로 처리하기 때문에 I/O가 많은 작업에 유리함
- CPU 작업이 많은 경우에는 callback queue에 있는 것이 실행되지 않기 때문에 좋지 않다.
- 가볍다.
spring
- spring은 CPU 작업이 많은 경우가 좋다. 연산이 많은 경우 thread를 사용해 명시적으로 처리할 수 있기 때문에 효율적.
- type-safe하다.
- 실행에 오래 걸린다. (JVM, GC)
- 플랫폼 독립. (jvm 위에서 돌 수 있음)
- thread 생성 위해서는 개발자의 관리가 필요함.
성능상 큰 차이는 없을 것 같다. spring에서 thread 생성해서 오래 걸리는 작업을 multi thread로 돌리면 되는 것 아닌지?
spring은 thread pool을 사용해 thread를 관리함. 내부적으로 몇 개의 thread를 미리 생성해 둠. 이후 필요한 작업에 할당했다가 돌려 받음. (thread를 생성/삭제하는 게 OS, JVM에 로드를 많이 주고, 무한히 생성할 수도 있기 때문.)
1. 초기에 정해진 크기만큼 thread 생성함
2. 사용자 요청이 들어오면 queue에 담아두고, idle 상태(놀고 있는) thread가 있으면 queue에서 꺼내서 작업을 thread에 할당함.
- idle인 thread가 없다면 작업은 queue에서 대기, 만약 queue가 가득 차면 thread 새로 생성.
- task 완료 시 thread는 idle 상태로 돌아가고, queue가 비고 thread가 초기 개수보다 더 많다면 destroy.
=> 미리 만들어 놓고, 필요한 작업에 할당했다가 돌려받음.
JPA & Transactional & Test annotation
@transational
해당 메소드가 transation이 되게 보장해줌. 여러 DB 쿼리가 있으면 이것들을 transaction으로 묶음. 하나라도 문제 발생 시 롤백. 종료 시 commit().
여러 개의 transactional이 있는 경우, 격리 수준을 사용해서 해당 리소스에 접근. 순서는 jvm 스케쥴링에 따름.
rollbackfor option : 기본적으로 unchecked exception만 롤백하기 때문에 exception도 롤백하게 지정
readonly option:
(일반적으로) entity가 영속성에 영속될 때, 해당 entity의 상태를 snapshot으로 남긴다. snapshot과 entity 상태를 비교해 변경된 내용만 update query를 모아 DB로 날린다.(이게 dirty checking이다!) transactional이 붙은 method는 트랜잭션 commit 시 DB에 flush함.
readonly true : dirty checking 발생 X. read 한 이후 DB로 flush하지 않는다. (snapshot을 찍지 않기 때문에 변경사항 감지 X. 때문에 메모리 절약도 가능) 때문에 변경사항 반영 안 되는 것으로 알고 있다.
---
slice test : 특정 계층만 처리 가능. @springboottest : 전체, @webmvctest: controller, 등
@test
junit에서 test annotation 다 모아서 테스트 돌려줌.
@springboottest
spring에서 bean 등록한 것들 "다" 모아서 injection해줌.
테스트 코드에서 @transactional 쓰면 쿼리 날린 것 다 롤백해 줌. (안붙이면 롤백안됨)
bean 등록한거에서 가져오고 싶으면 @autowired 쓰면 됨
@webmvctest
controller 관련만 로드함. @mockbean 만들고 리턴값 정의해서 써야 함.
플젝
SW개발병
육군본부 운영지원과에서 내부 WAS를 유지보수하는 일을 했다. 주로 추가 요구사항 구현, 버그 픽스, 보안 취약점 수정 등을 진행함.
어떤 일을 했는지, 내부 구성은 어땠는지, 어떤 일이 제일 기억에 남았는지
- 내가 어떤 과에서 뭘 유지보수했고, 어떤 걸 유지보수했으며, 어떤 이슈가 있었고, 어떻게 고쳤는지.
육군본부 내부에서 사용하는 웹 서버를 유지보수 했습니다. 서버 자체는 내부에서 띄워주고, 어떤 방식으로 띄우는지는 알 수 없었다. 주로 추가 요구사항 구현, 버그 픽스, 등등 업무를 진행했다.
내부 코드는 전자정부프레임워크 3.2를 사용한다. 2014년도에 나왔네..
직접적으로 티켓같은 걸 맡지는 않고 파견 형식이라 처리하는 방식.
로컬 환경 구성은 조금 어지러운데, 내부 규칙으로 인해서 java 파일을 올리지 못한다. 그래서 컴파일된 .class 파일들만 다 올라가 있는데, 그것들을 디컴파일해서 오류 수정하고 처리했다.
젤 힘들었던 것 : 로컬 구성 + 인수인계 + git 없음
+ 소마는 왜 했는지 - SW개발병 가려고 했다고 했다.
쿼리 최적화는 어떤 거 했는지 : 쿼리 최적화 포스트
- 타이밍 + 권한이 없어서 추가 분석 못한 게 아쉬움.
MVC 구조는 뭐고, 어떻게 수정했는지, 얼만큼 수정했는지 기존 코드는 controller에 모든 코드가 다 있어서 service repository로 분리했다고 했더니, 굳이 나눌 필요가 있나요? 라는 질문이 들어왔다. 유지보수하기 편하게 하려고 그렇게 했다고 답했다. 하나에 다 몰아두면 뭐가 뭔지 구분하기 힘드니까.
보안
XSS, SQL Injection, path traversal, web shell
XSS는 동적 웹 페이지의 입력 폼에 javascript 명령어를 넣는 등의 방식을 통해 해당 페이지에 접근하는 사용자의 브라우저에서 악의적인 스크립트를 실행시키는 공격 방법이다.
가장 쉬운 해결방법은 모든 입력값에 대해 <, >, ", '와 같은 script에서 사용하는 특수문자를 HTML character entity refernce로 바꾸는 방법으로 바꾸는 것이다. < → < > → > " → " ' → ' 이 경우, 모든 사용자 입력값에 대해 검증해야 하기 때문에 코드가 난잡해질 수 있으며 사용자가 html을 입력할 수 없다는 단점이 있다. 그러나 난잡한 코드는 servlet filter로 대체할 수 있고, 사용자가 직접 html을 입력하게 하는 대신 개발자가 설정한 특정 태그만 white-list로 열어두던지, 아니면 정해진 format으로만 출력되게 하는 방법이 있을 것이다.
SQL Injection은 사용자가 입력한 값이 필터링이나 이스케이핑 없이 DB로 들어가는 경우에 할 수 있는 공격 방법이다. 변수가 바로 SQL문에 들어가는 경우 주석처리나 OR 등의 연산자를 통해 원하는 SQL을 실행할 수 있게 된다.
가장 쉬운 해결방법은 prepared statement를 사용하는 것이다. prepared statement가 무엇인지 설명하려면 그것만으로도 포스팅 하나가 나오니, 간단하게만 설명하자면 "SQL 캐싱을 통해 사용자 입력을 순수 문자열로만 치환해서 SQL을 날리는 방법"입니다. SQL Injection을 막아줄 뿐만 아니라 캐싱해두기 때문에 같은 SQL을 실행시킬 때 시간이 단축된다는 장점도 있다.
Path Traversal은 파일 다운로드 시 파일 이름을 이용한다는 것에 착안하여 window의 경우 ../이나, unix의 경우 ..\와 같이 상위 폴더로 움직여 시스템의 중요한 정보를 탈취할 수 있는 공격 기법이다.
가장 쉬운 해결방법은 사용자 입력에 ../, ./, .|, ..|, ..\, .\, ||와 같은 특수문자가 있으면 지워버리거나 접근을 차단하는 방법이다. 단순히 ../를 공백으로 치환해버린다면 ....//와 같이 여러 번 중첩해서 사용할 경우 뚫릴 위험이 있기 때문이다.
Upload Attack은 첨부파일과 같이 사용자가 파일을 서버로 업로드하는 기능을 악용해 서버에서 실행되는 .jsp나 .php와 같은 스크립트를 업로드하고, 해당 스크립트를 통해 서버측의 권한을 탈취할 수 있다. 여러 방어를 우회하기 위해 a.jsp.jpg와 같이 확장자를 2개 붙이기도 하고, a.jSp와 같이 대소문자를 바꿔넣기도 하고, a.jsp%00.jpg와 같이 null 문자열을 중간에 넣기도 한다.
가장 쉬운 해결방법은 업로드한 파일 이름의 뒤에서부터 검사하고, white-list 방식을 사용하는 것이다. 다른 방법은 파일 이름을 저장할 때 내부 저장값으로 인코딩/디코딩 하는 것이다.
쿼리 최적화
어떤 쿼리를 최적화했으며, 어떻게 바꿨고, 왜 그렇게 바꿨고, 왜 그렇게 생각했는지.
쿼리 최적화 포스팅에 있는 내용대로 말했다. 일단 실행계획 봤더니 nested loop으로 도는 것 확인해서 nested for loop 3중이라서 오래 걸렸고, 때문에 join으로 바꿨다고 말했다.
왜 join을 선택했냐는 질문에는 일단 nested loop를 없애야 한다고 생각했고, join 이후 필터링한 값을 사용하면 불필요한 반복문이 생기지 않고, + table size가 작아 join overhead가 크지 않을 것이라 생각했다.
시간복잡도는 제껴두고, nested for loop의 경우 A join B면 A + AB이고, hash join같은 경우는 A + B로 처리된다. 3중이니까 A join B join C면 A + A(B+BC)니까 A + AB + ABC인데, join이면 A+B+C로 처리된다. 이런 page 개념으로 시간복잡도를 설명.
쿼리 옵티마이저가 어떤 방식으로 동작하는지도 물어봤다.
DB 정규화
| 접수번호 | 주민번호 | 종류 | 상해등급 | 민원등급 | |
| 1 | ******-******* | 민원 | null | 3급 | |
| 2 | ******-******* | 의무조사 | 1급 | null | |
| 3 | ******-******* | 민원 | null | 4급 |
DB 정규화 & 리팩토링
- 요구사항 : 보통전공상심사관리체계 - 기존 현역/공익 타입으로 입력을 받고 있었는데, 입력 페이지가 1개였다. 현역인 경우 상해등급에 값이 있고, 민원등급인 경우 민원등급에 값이 있다. 그러나 입력 페이지가 1개여서, 현역인 경우에는 민원등급에 값을 비워 쓰고, 민원등급인 경우 현역등급에 값을 비워 쓰고 있었다. 이게 불편하다는 요구사항이 있었다.
- 정규화 한 이유 : 종류가 상해등급/민원등급의 null을 결정. 또한 DB 컬럼이 매우 많고, 자주 사용하는 것들만 사용하기 때문에 overhead가 너무 클 것이라 생각. 실제로 로딩에 오래 걸리기도 하고.
기존 테이블 - 접수번호가 다른 것 모든 것을 결정.
이 테이블은 0NF. null 값이 존재하기 때문. 그것만 없으면 모든 값이 원자값이고, key가 접수번호이기 떄문에 부분적 함수 종속이 없다. 그러나 이행적 함수 종속 (pk id -> 접수번호 -> 나머지) 가 있기 때문에 1NF.
물론 null값이면 1NF를 만족하는지 여부는 논쟁 중이긴 하지만, 나는 그렇게 생각한다. 여기서는 반면 접수번호로 종류, 종류로 상해등급의 null 여부를 알 수 있다. 반면 종류가 민원이냐, 의무조사에 따라 식별하지는 못하지만 null값이 되는 column이 있기 때문에 이를 고쳐야 한다고 생각했다.
때문에 [접수번호, 종류, 주민번호]와 같이 공통된 부분을 묶고, 나머지를 따로 떼서 다른 테이블을 만들었다. vertical partitioning의 방법을 사용해 anomaly를 없앤 것이라 보면 될 것 같다.
id를 long으로 두는 이유는, 비즈니스 정보를 id로 두는 경우 해당 정보가 수정될 수 있는 상황이 올 수도 있기 때문. 또한 long으로 두면 auto_increment로 관리하기 쉽고, id는 숫자이기 때문에 문자보다 비교 속도도 더 빠르기 때문.
리팩토링
정규화와 이어지는 부분. DB가 바뀌었기에 repository 역할 하는 XML도 변경, XML 사용하는 service도 변경. controller에서는 기존 페이지 구조를 같게 해야 한다는 요구사항이 있어 controller는 하나로 둠.
하나의 URL로 두 종류의 값을 받아야 하는 것이 기본 요구사항.
1. controller에서는 super DTO를 사용해 두 종류의 값을 모두 받는다. 아래와 같은 느낌이다. 여기서 if-else문을 strategy pattern으로 해결했다. return url도 같은 방식으로 map에 넣어서 해결. 내부 들어가는 것에 대한 처리는 service 내부에서 해 줬다.
2. service는, 공통 양식 로직을 처리하는 DutyService, 이를 상속하는 ActiveDutyService와 ReserveDutyService 2개로 나누어, 세부 구현을 맡겼다. template method pattern이다. 변하지 않는 공통 부분은 묶고, 변하는(type에 따라 다른) 부분만 위임해서 해당 repository를 호출하는 식으로.
3. template method는 abstract class와 inheritance와 override를 사용하는 방식, strategy는 interface와 polymorphism을 사용하는 방식이다. strategy pattern은 동적으로 type을 선택하기 위함, template method는 공통 부분을 사용하기 위함. 여기서는 abstract class를 사용하긴 했지만, polymorphism을 썼다.
공통 부분을 가져오는 로직이 있는데, interface를 쓰면 이 부분이 중복되기 때문에 abstract class를 썼고 - 따라서 template method가 적용된 것이고, 각 type별로 넣는 부분이 있는데, 이 부분은 type별로 따로 써야 하니까 processDuty()를 override하는 방식으로 - 따라서 template method가 적용된 것이다.
strategy pattern은 type을 동적으로 가져오기 위해 사용했다. - controller에서 쓰인 것. controller가 service를 호출하는 것이 역할이라고 생각해서 service 내부에서 service 호출하지 않고, controller에서 service 호출하게 함.
@PostMapping("/processPerson") public ResponseEntity<String> processPerson(@RequestBody PersonDTO personDTO) { if ("ActiveDuty".equals(personDTO.getType())) { activeDutyService.processDuty((ActiveDutyDTO) personDTO); } else if ("ReserveDuty".equals(personDTO.getType())) { reserveDutyService.processDuty((ReserveDutyDTO) personDTO); } return ResponseEntity.ok("Input processed successfully"); } @RestController public class YourController { private final Map<String, DutyProcessingService> dutyProcessingMap; public YourController() { dutyProcessingMap = new HashMap<>(); dutyProcessingMap.put("ActiveDuty", new ActiveDutyProcessingService()); dutyProcessingMap.put("ReserveDuty", new ReserveDutyProcessingService()); } @PostMapping("/processPerson") public ModelAndView processPerson(@RequestBody PersonDTO personDTO) { DutyProcessingService dutyProcessingService = dutyProcessingMap.get(personDTO.getType()); if (dutyProcessingService != null) { PersonDTO resultPersonDTO = dutyProcessingService.processDuty(personDTO); ModelAndView modelAndView = new ModelAndView(); modelAndView.setViewName("/.../" + dutyProcessingService.getViewName()); modelAndView.addObject("person", resultPersonDTO); return modelAndView; } else { // 유효한 유형이 아닌 경우 처리 return new ModelAndView("error"); // 에러 페이지로 리다이렉트 또는 에러 처리를 할 수 있습니다. } } }
위 코드는 접은글 1번의 코드.
소마
프로젝트 : 법인의 임직원들이 복지 용도로 사용할 수 있는 통합 공유킥보드 플랫폼
무슨 프로젝트를 했고 어떤 과정이 있었는지, 어떤 기술을 썼는지, 쓰면서 힘든 점은 없었는지, 팀 빌딩은 어떻게 했고 주제는 어떻게 골랐는지 : 소마 회고록에 있는 내용 거의 다 말했던 것 같다.
- CRUD 말고 API 몇개 정도 만들었는지 : 통계 3개, 계약, 사용 CRUD정도 말했다.
기술 선택은 어떻게 했고 jenkins pipeline은 어떻게 구성했는지, 막힌 점은 없었는지, yaml 파일 쓰면서 어려운 건 없었는지 : hook 따오고 gradle build, gradle test, sonarqube 분석, gcr image push, clean까지 했었다고 답변했다. CI를 하지 않은 이유는, push를 한 시점 == 배포 시점이 되면 안될 것 같아서 배포를 위해서는 저장한 image를 GKE에서 명령어 쳐서 배포하는 방식으로 했다.
왜 GCP 썼는지 : 익숙해서 사용했다고 했다. 학교 딥러닝 프로젝트 하면서 그래픽카드가 필요했는데, 2019년도즘? GCP에서 GPU 포함 30만원 정도 크레딧을 줬다. (작년까지도 준 것으로 안다) 그래서 그때부터 잘 사용했다.
redis는 왜 썼는지 - login token을 jwt로 구현했는데, logout 검증하려고 사용했다. 토큰 기반 인증 사용한 이유는 pod 여러 개 두려고 사용했다고 했다.
- 추가 질문 - redis 날아가면 어떻게 처리할 건지 물어봤다. 고민해보지 못한 점. 원했던 건 분산처리나 백업이었던 것 같다. replica 만들던가, dual로 동작시키던가 하는 백업 방안을 원했던 것 같다. 그리고 나는 access token, refresh token 모두 redis에 뒀는데 refresh는 DB에 둬야할 것 같다.
k8s 사용하면서 어땠는지 - 배포 알아서 해주고 로드밸런싱 해주니까 좋았다고 답변했다.
사실상 새로운 기술을 사용하면서 느낀 점은 많이 편하다...가 거의 대부분이었는데, 더 질문이 들어와서 좀 어려웠다.
Bizkicks에서 JWT/redis
bizkicks에서는 access token + refresh token을 사용했다. redis를 사용한 이유는 scale out을 위해서인데 해당 부분은 구현하지 않았다. refresh token만 redis에 넣는다.
- login 요청이 오면 access token + refresh token을 돌려준다.
- access token + refresh token으로 reissue한다.
- 모든 접근에는 access token만 사용한다. 만약 만료될 경우 refresh token을 보내서 reissue한다. 만약 틀리다면 작동 안되는 식이다.
- refresh token은 redis에 들어가 있다. refresh token을 받아서 reissue하는 방식이기 때문에 자주 불릴 것이라 예측했고, 따라서 빠른 in memory DB인 redis에 넣었다. 또 만료 시간을 DB가 관리해 준다는 장점도 있었다. (DB의 부하 감소)
- refresh token이 없다는 것은 로그아웃된 상태임을 시사한다.
meerkat에서는 access token만 사용했다. token 인증 방식이다.
redis의 사용 이유는
- in memory DB라 속도가 빠르며, 사용자 token이라는 간단한 정보만 넣기 때문에 key-value store가 적당하다. 그리고 시간도 알아서 관리해 준다.
- 정보가 많다.
- 이후 확장할 때 pub/sub 구조 등을 활용해서 jwt 처리하기가 다른 DB보다 쉽다.
단점
- in memory DB이기 때문에 날아갈 수 있다. 그러면 reissue 로직에서 redis에 있는 값을 보는데, 없기 떄문에 로그아웃 처리가 된 것으로 했다. 따라서 access token의 만료 시간인 15분에 한 번씩 로그인해 주어야 한다는 단점이 있다. memory DB이기 때문에 불안정하다는 단점은 replica를 만들던가, dual로 동작시키던가 하는 방법이 있을 것이다.
추가적으로 refresh token 관리
기존 코드에서 redis에 access token, refresh token 둘 다 넣었는데 redis가 날아가는 상황을 고려하지 않았다. 좀 더 안정적인 서비스를 위해서는 refresh token을 DB에 넣는 것이 더 좋을 것 같다. 어차피 refresh token은 access token이 만료되는 상황에서만 불러지니까 그렇게 load도 심하지 않을 것이다.
탈취
access token 탈취 시 해킹에 의한 피해를 줄이기 위해 지소시간이 짧은 access token을 사용한다. 그러나 refresh token이 탈취당하는 경우에는 access token을 재발급할 수 있으므로 피해가 커질 것이다.
이를 해결하기 위해 refresh token rotation 기법을 사용하는데, access token이 만료되어 refresh받을 때 refresh token도 재발급하는 방법이다. 그러나 이 방법의 경우 해커가 먼저 refresh를 하는 경우에 문제가 발생한다. 때문에 DB에 저장할 때 user id : refresh token 이런 식으로 저장해서 refresh token이 단 하나만 존재할 수 있게 한다. 이후, refresh 요청을 보냈을 때 refresh token이 저장된 것과 다르다면 해킹 시도로 간주하고 로그아웃시키는 방법이 있다.
- 이 경우 해커가 refresh token을 탈취했을 때, 사용자보다 늦게 로그인하면 로그아웃 처리가 되고, 사용자보다 빨리 로그인하면 사용자가 로그인했을 때 로그아웃 처리가 된다.
- 그러나 사용자가 로그인하지 않는 경우에는 해커는 사용자 정보로 계속 활동할 수 있게 된다. 그러나 이는 토큰 방식의 필연적인 한계라 생각한다. 해결 방법으로는 refresh token의 유효기간을 두는 것. (로그인 시 7일 이후에는 새로 로그인해야 하는 등)
미어캣
미어캣 : E2EE를 적용한 안전한 실시간 채팅 앱
누구랑 어떤 프로젝트 했는지, 왜 만들었는지, 기술 선택 이유는 무엇인지 - mariadb 쓴 이유는 뭔지, orm은 왜 썼는지, 어디까지 구현했는지, 채팅 어떻게 구현되었는지
ORM 얘기. 이거 좀 많이 했다.
- ORM을 왜 쓰는지 ? 확장성이나 유지보수성 + DB가 바뀌었을 때 쉽게 대처할 수 있다고 했다. 답변으로는 실서버에서는 DB를 바꾸는 일이 극히 드물다. 그래서 사실 DB를 바꿀 수 있어서에서 오는 장점은 거의 없고, 읽기 쉽고, 테이블이 단순해지고, query를 직접 안 쓰니까 코드 레벨에만 더 집중할 수 있다가 맞는 대답인 것 같다. 혹시나 DB를 바꾸는 상황이 되었을 때도 의존성을 줄일 수 있을 것이다.
- ORM을 왜 적용했는지 : 나는 시간 없어서 안쓰는 게 맞다고 했는데 다른 팀원들이 꼭 써야 한다고 해서 수긍했다고 했다.
git 전략: rebase
docker 사용하면서 어땠는지 - 편하다고 했다. 살짝 마음에 안 든 것 같긴 하다. 추가로 이후로 모든 db나 환경 docker에 올렸다고 대답했더니 db도 올려 쓴거냐고 물어봐서 서비스당 각 db에 해당하는 걸로 올려썼다고 했다.
백만 했냐고 물어봤다 : 시간이 없어서 react로 친구 페이지, 채팅방 목록 부분을 내가 만들었다고 했다.
인증은 어떻게 했는지 : token으로 관리한다고 했다. + 모든 socket에 token을 넣어서 관리하는 식으로 했다.
E2EE?
비대칭키 암호화 : 공개키로 암호화 한 것은 개인키로만 복호화 가능. 그 역도 마찬가지. 내부적으로는 소인수분해 사용하는 RSA 쓰는 것으로 알고 있다.
암호를 만들 때 두 소수의 곱으로 만드는데, 이 때 사용한 두 소수를 찾기 힘들다. 숫자가 n일 때 n 아래의 소수를 찾는 데 nloglogn, 이는 모두 있다고 해도 O(n)이 걸림.
암호화
RSA 원리
디피헬만 간단히
salt
소인수분해 문제 : RSA
이산대수 문제 : 디피헬만
RSA
큰 정수의 소인수분해가 어렵다는 점을 활용. 비대칭키 방식. 공개키를 사용해 암호화/개인키를 사용해 복호화 또는 개인키를 사용해 암호화/공개키를 사용해 복호화 가능
개인키로 서명해서 송신자가 인증한 것을 알 수 있음
공개키 암호화 공격 시나리오
1. A, B가 메시지를 교환할 때, 해커가 B의 공개키를 탈취해 A에게 C의 공개키를 보냄.
2. A는 C의 공개키로 평문을 암호화해 B에게 보냄
3. C는 C의 개인키로 복호화하면 A의 평문을 습득할 수 있고, 이를 B의 공개키로 암호화해 B에게 보냄
4. B는 평문을 얻지만, 이미 탈취당함
디피헬만
대칭키 교환 시 사용. 키 값을 전달하는 것이 아니라 키 값을 만드는 방법을 전달함.
일방향
MD5
SHA256 : 충돌 걱정을 안 해도 괜찮은 해싱 방법
salt
비밀번호 암호화 시 평문을 그대로 저장하거나, 복호화할 수 있는 방법을 사용하지 않고 해싱으로 복호화 불가능하게 저장. 이 때 salt를 추가로 평문에 붙여서 해시 결과를 알 수 없게 하는 것.
실시간 채팅
채팅 구현 내용 : 채팅방에 속해있는 사람들은 어떻게 구현했는지, 실시간 채팅인지, socket 썼는지. 있는 그대로 얘기했다. 자료
클라이언트에 2개의 socket 연결을 이용하는데, 하나는 실시간 메시징을 위해서이고 나머지 하나는 메시지 수신에 대한 알림을 위해서. 지금 생각하기로는 채팅방 목록에서 알림 오는 거는 클라가 요청을 보내지 않고, 응답을 받기만 하면 되므로 SSE 같은 걸 쓰면 좋았을 것 같다.
모든 사람이 자신이 속해있는 모든 socket room에 join하고, 메시지 보내거나 받는 event 발생 시 read event를 발생해 최신의 읽은 메시지를 갱신하고, DB에는 모든 사람이 어떤 방에 속했는지, 각 방에서 채팅내역을 모두 보낸다.
그래서 실시간이고, E2EE 적용한 내용을 말했다.
- 그러면 사람마다 안 읽은 메시지 개수가 다를 수도 있지 않나? 음.. 그런 경우가 있나요? DB에서 메시지 관리하고, socket도 관리하는데, dual로 관리하는데 그런 일은 안 생길 것 같다고 답했다. 서버가 터지지 않는 이상!
SSE
polling : 클라가 서버로 일정 시간마다 데이터 요청을 보내는 방식.
long polling : 클라가 요청을 보내고, 서버에 event 발생 시 클라에게 응답하는 방식. connection이 유지되어 있어야 한다.
websocket : 실시간 연결, event 방식
websocket과 유사, client가 server로부터 데이터를 받을 수만 있음.
N2T
naver to tistory 이사 프로그램
왜 구현했는지 : 왜 구현했는지, 어떻게 구현했는지, 왜 java 썼는지에 대해 질문받았다. 있는 그대로 답했다. 필요해서 만들었고, java 공부하고자 썼다고 대답했고, 왜 CLI 썼냐는 질문에는 front 잘 못해서 그냥 cli로 깔끔하게 처리하는 게 좋을 것 같아서 그랬다고 했다.
추가 질문으로는 text만 긁어서 올린거냐고 물어봤는데, style 등 전부 다 파싱해서 올렸다고 했다.
비공개 포스트는 어떻게? 이거 하려면 사용자에게 id/pw 요구해야 하는데, 너무 사짜같아서 비공개는 배제했다. 티스토리에 올리는 건 token만 있으면 되기 때문에 이건 괜찮을 거라 생각했다.
- 필요없는 주석들이 너무 많았다.
- try-catch문을 너무 많이 사용해 가독성이 떨어진다는 느낌을 받았다.
- concrete class에 의존한다. 때문에 확장성이 없다시피 했으며 유지보수도 힘들었다.
- if-else문으로 대부분의 로직을 처리한다.
- 테스트 코드가 없다. 때문에 소스코드를 수정한 후 검증하는 과정이 오래 걸린다.
- 주석 삭제. 의도를 설명한 주석, 유지보수 시 참고가 될 만한 주석만 남기고 모두 삭제. JavaDoc은 필요한 public 함수에만 남기고자 했다.
- 예외처리를 간소하게. 곳곳에 퍼져 있는 try-catch문을 응집시키고자 했다.
- 최대한 의존성을 줄이고 확장성 있게 코드를 작성하고자 했다
- 테스트 코드 작성
N2T 리팩토링
추후에 리팩토링했다는 이야기도 했다. 처음에는 if-else문이 너무 많게 구현했는데, 공부하다가 확장성 이슈를 크게 느껴서 implement로 구현했다고 했다. 그래서 기능 추가나, 목적지 블로그 추가해도 전체 구조는 동일하게 된다고 어필했다.
EME
intellij 마크다운 wysiwyg editor. 편집할 때 실제 렌더링된 결과를 보여줌. (like obsidian)
easy markdown editor
해당 프로젝트 : agile을 배우는 게 주 목적이어서 주간 회의, story point 할당, 배분, 구현 같은 것을 했다.
intellij에서 마크다운 에디터를 구현하는 것이 목적. 기존 default로는 미리보기를 위해서는 화면이 반반 나뉘며 공간을 많이 차지한다. 기존에 플러그인은 있지만, 문제점이 많았다. 탭 전환할 때 무한루프에 걸리는 건지 모르겠는데, 전환이 안 되었다. 컴퓨터 성능 모니터링 결과 성능을 크게 잡아먹는 것 같지는 않았지만, 몇몇 컴퓨터에서 이러한 문제가 발생했고 사용할 수 없는 문제가 있어 이를 해결하고자 했다.
주제 냈음, 초기 컨벤션 잡고, 전체적인 클래스 구성도 및 구현 방식 디자인, 로직 설계/작성, 테스트코드 작성, 등등 모든 부분에 관여함. 그런데 나만 이렇게 한 건 아니고 모든 팀원이 다 적극적으로 참여했다.
사용한 패턴 : observer pattern, template pattern
설명할 수 있을 정도로 준비
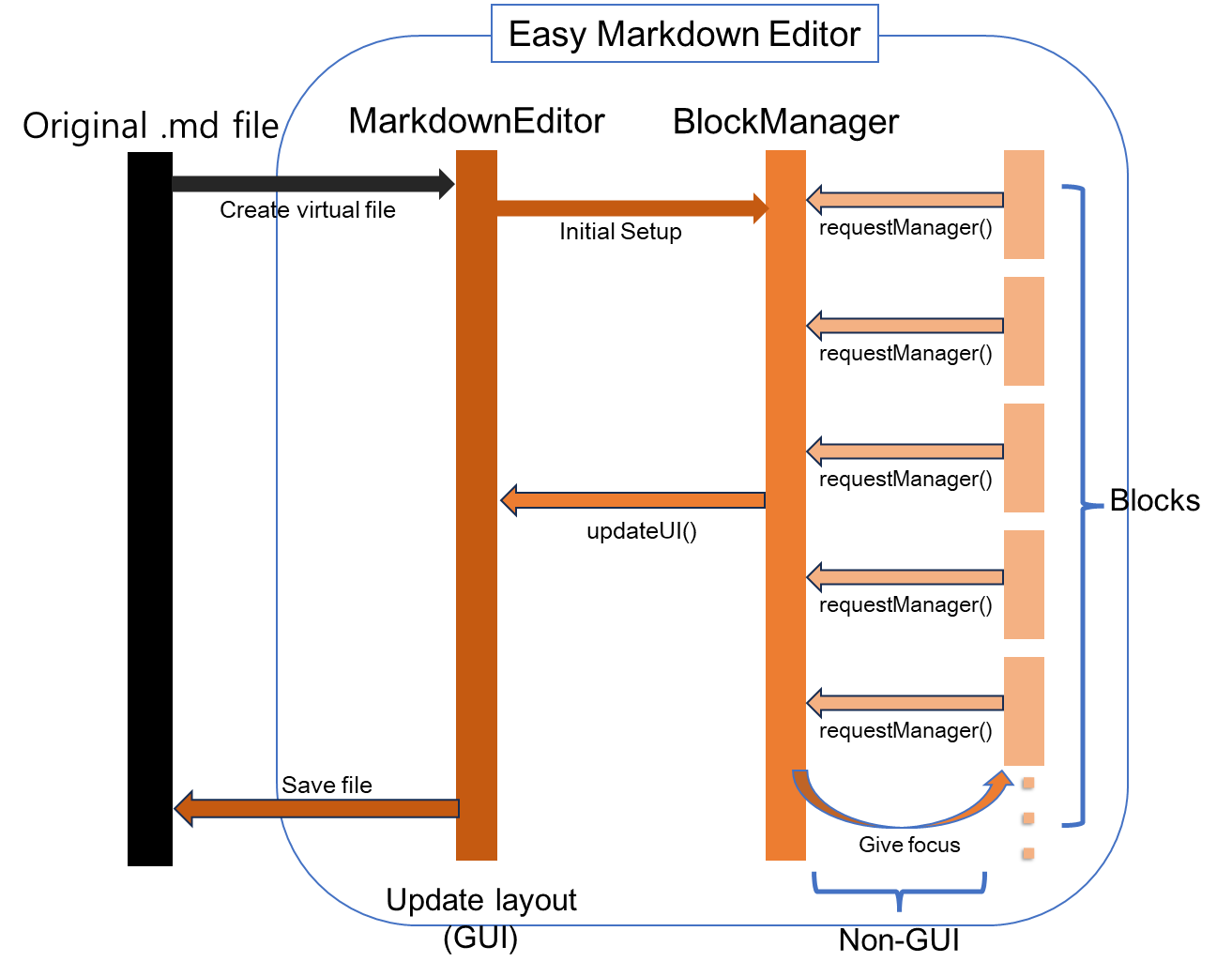
전체 구조도. 각 block들이 blockmanager에 notify하면 blockmanager 내부에서 markdownEditor의 updateUI()를 호출하는 식으로 구현. 내부적으로는 각 block에서 마우스 클릭 이벤트 / 키보드 클릭 이벤트를 listen하고 있음.
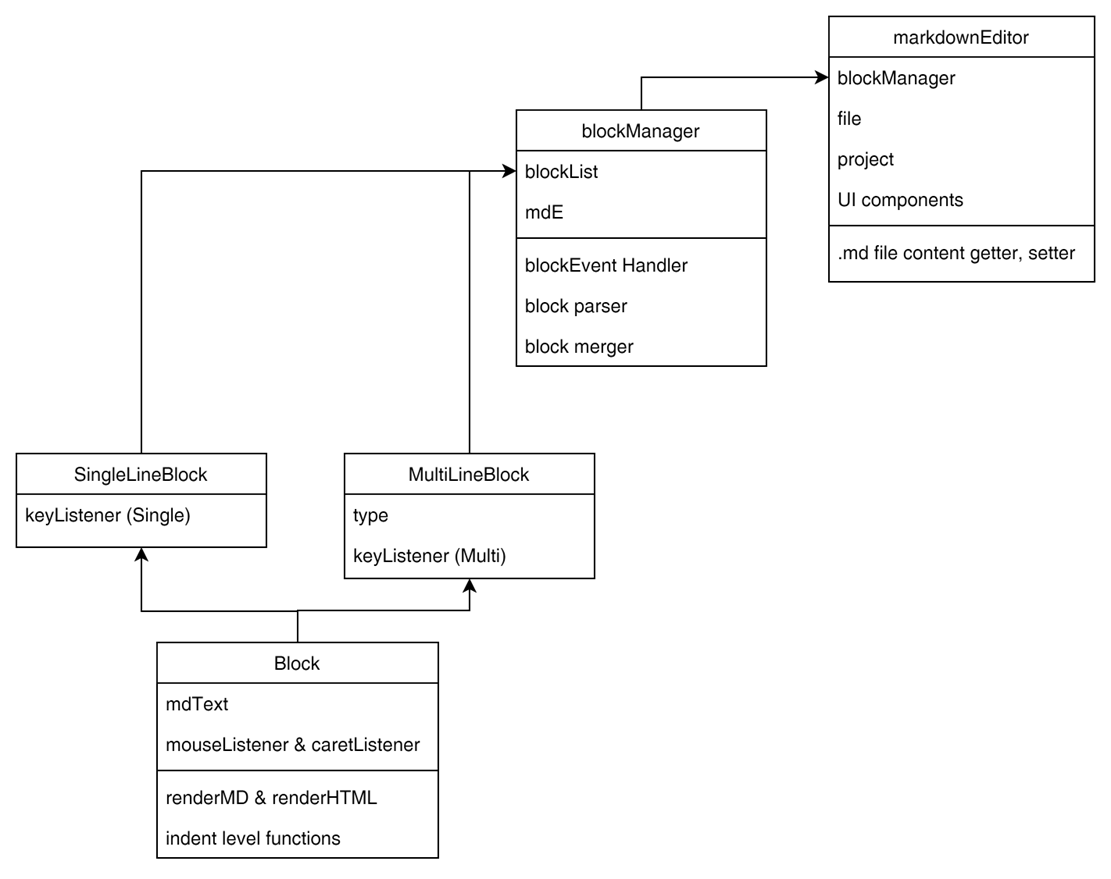
클래스 구조도. block은 abstract이고, 한 줄짜리로 처리 가능한 heading/horizontal line 같은 것을 처리하는 게 single line block. quote/codeblock/ul/ol 등을 처리하는 게 multiline block.
이렇게 마크다운을 여러 개의 block으로 나누고, focus된 block들만 markdown raw text로, 나머지는 html 렌더링. focus된 block에서 뭔가 이벤트가 발생한 경우, 각 케이스에 대해 처리를 했다.
- 다른 block이 클릭되는 경우 outfocus_click 이벤트를 날려 focus block을 변경
- 제일 상단에서 키보드 위 화살표나 제일 하단에서 키보드 아래 화살표가 눌리는 경우 outfocus_up, outfocus_down 이벤트를 날려 focus block 변경.
- 제일 뒤에서 엔터를 누르는 경우 new_block 이벤트를 날려 새 블록 생성 후 포커스 변경
- 제일 앞에서 delete를 누르는 경우 해당 블럭을 이전 block과 merge
- 중간에서 엔터를 누르는 경우 내용을 판단해 transform_multi나 transform_single 이벤트를 날려 적당한 block으로 변환
GUI 빼고 line coverage 90% 달성. 학점도 A+ 받음.
인성면접
- 개발자 선택 동기 : 대학원(AI, 시스템, 이론), 개발 시도하면서 개발동아리 하나 했는데, 하면서 적성에 잘 맞았다. 처음에는 주어진 API를 짜는 것 자체에서 재미를 느꼈는데, 하면 할수록 잘 만드는 것(요구사항을 잘 분리하고, 구조를 잘 짜고, 하는 것들)이 적성에 맞다고 느꼈다. 이후 소마, SW개발병 하면서 확신 들어서 결정.
- 어떤 게 좋은 코드일까? :
- 함수는 - 잘 읽히고, 수정하기 좋은 코드. 보편적인 가독성 좋은 코드란? 너무 길지도, 너무 함축적이지 않은 변수명을 사용하면서 + 함수에 parameter도 너무 많지 않으면서 (많은 경우에는 객체 하나 써서 wrapping + 적절한 이름으로 네이밍) + 하나의 로직 내에 너무 깊은 depth가 없으면서, (많은 분기문&try-catch가 없으면서, 있더라도 depth 1칸, 최대 2칸 정도) + 다른 method를 호출할 때 method 이름도 너무 길지도, 너무 함축적이지 않은 이름을 사용하는 함수 + 너무 가로로 길지도, 너무 세로로 길지도 않으면서 + 각 문단이 잘 구분되어있는 함수가 좋은 코드라 생각함.
- 전체적인 구조로는 - 전체적인 depth가 너무 깊지 않으면서 + 공통 모듈을 제외하고는 하나의 메소드가 너무 다양한 도메인에서 불리지 않으면서 (유지보수하기 힘듬) + 레이어의 구분이 잘 되어 있는? 구조가 좋은 코드라고 생각한다.
- 레이어 : 도메인형 구조는 도메인 하나에서 사용하는 각각의 controller, service, repo, entity, dto 구분. 그러나 도메인이 섞이는 경우 복잡. (join 등) layered는 layer별로 구분. 그러나 파일 많아지는 경우에 복잡.
- 가장 어려웠던 경험(벽 느낀 경험) : 현실적으로는 비즈킥스 프로젝트 진행하면서. 코드 짜면서는 아키텍처.
- 기억나는 수업 : OR, 객체지향, 자료구조, 아키, DB, 알고리즘
- 자신의 장단점 :
- 집념? 목표 달성에 있어 집념있는 편. 어떤 일을 진행할 때, 해당 일의 큰 데드라인 + 자잘하게 일을 나눠서 목표를 설정한다. 목표 자체에 2일 정도의 여유 기간을 두긴 하지만 목표 자체를 달성하는 데 집념이 있다. 예를 들어 제일 힘들었던 과제인 pipelined CPU 구현 같은 경우, pair programming 했는데, 정말 잠만 자고 코딩만 했다. pair 끝나고 나서도 혼자서 추가로 구현하기도 했다. 여러 일들을 겪으면서 최근에는 목표를 타이트하게 설정하고 스트레스 받아가면서 작업하니 남는 시간에 반동으로 더 휴식을 추구하게 되었다. 그래서 조금의 여유를 두고 지속할 수 있을 정도의 부담감만 느끼는 수준으로 목표를 설정하는 쪽으로 유연하게 변경 중이다. 한편, 이 집념이 내가 맡은 어떤 일과 목표의 완수, 즉 성장과 향상심에 대한 집념이지, 의사소통에 있어 고집이 세다 이런 쪽의 집념은 아니다. 오히려 이러한 의사소통이나 충돌 같은 것에 있어서는 정말 아니다로 생각하는 것을 제외하고는 대부분 접고 들어가는 편. 대표적으로 프로젝트 기술 스택 정했을 때 팀메이트는 orm 써야 한다였는데, 나는 아니었다고 한 것. 정말 아니다라 생각하는 것 중 하나는 컨벤션. 컨벤션이라는 게 결국 팀메이트들과의 약속인데, 이를 어긴다는 건 결국 사회적 약속을 깨는 거라 생각한다. 혼자 형식 안 맞는 것도 좀 그렇고. 다른 하나는 마무리 제대로 안 하는 것? 플젝 끝냈거나 어느 정도 완성되었다면 나머지 디테일을 챙겨야 한다고 생각한다. readme나 문서, 주석 정리 등등. 이런 것들은 오히려 좋아.. 내 맘대로 할 수 있어서
- 단 : 몰입할 때는 100% 집중하는 것 같은데, 듀데이트 등 심리적 방해요소가 있으면 잘 못한다. - 때문에 항상 시간관리를 열심히 한다. + 잠이 많다. - 8-9시간은 자야 한다고 생각하는 사람인데, 때문에 깨어있는 시간과 계획 관리를 철저하게 한다.
- 의견 충돌 시 어떻게 해결할 건지 : 결국 의견 충돌이 나는 이유는, 현재 상황과, 특정 해결책의 장단점가지고 논쟁인데, 평행선을 이루는 이유는 확실한 근거가 부족해서라고 생각한다. 이런 상황에서는 진짜 논쟁을 하면서, 각자가 생각하고 있는 edge case에 대한 각각의 해결책들의 handling이 충분한지를 논의해보면서 더 좋은 방안을 채용할 것 같다. 만약, 그래도 해결되지 않는다면 다른 case들을 좀 더 고민해 보고, 최후의 최후에는 팀 내에서 다수결을 해야 할 것 같다. 그러나 다 잘하는 사람들끼리 모인 만큼 다들 비슷한 의견을 낼 것 같아서 그럴 일은 없을 것 같다. 그리고 최근에는 수긍을 많이 해서...
- 어떤 개발자가 되고 싶은지
- 회사에 대해 궁금한 점 : 테스트코드 쓰는 문화가 어떻게 되어 있는지, 코드리뷰 문화는 어떤지, 실제로 출근하는 분들이 많은지?
- 스트레스 관리법 : 잔다. 물론 낮시간이거나, 너무 급박한 일이라면 그렇지 못하겠지만, 어떻게든 충분한 수면 시간은 마련할 것 같다.
- 취미(여가) : 운동하거나 웹소설. 시간 좀 많이 남으면 게임하고. 유튜브 좀 본다. 쇼츠같은 건 아니고, 게임 영상이나 개발 영상 위주로 본다.
- 갈등관리 경험 (치어로, 포카풀) : 포카풀 일정관리 경험
- 회사에 들어와서 어떻게 성장하고 싶은지 : 최종적으로는 팀을 편하게 할 수 있는 만능 6각형 개발자로 성장하고 싶다. 일단은 각 능력치들을 조금씩 키우기 위해서 기존 코드가 어떻게 돌아가고 - 특히 트래픽 같은 것을 어떻게 처리하는지 공부를 하면서 작은 걸로 팀에 기여하고, 차근차근 기여할 수 있는 부분을 늘일 것.
- 원하지 않는 업무를 맡으면 어떻게 할지 : 백엔드가 아니라 아예 다른 작업을 시킨다면 고민을 많이 해보겠지만, 백엔드 메인 + 다른 일을 해야 하는 상황(어드민툴, 인프라 파이프라인 등)이라면 할 것 같다. 이런 일들은 원치 않는 업무라기보다는 해야 하는 일이라고 생각하기 때문. 나의 희망은 사용자와 가까운 도메인이지만, 처음부터 이런 부서에 배치를 받으면 나의 희망사항이어서 좋고, 사용자와 먼 도메인의 경우 오히려 이런저런 새로운 시도를 많이 해 볼 수 있을 것 같아서 오히려 좋다. 사용자와 가까울수록 코드 수정이 보수적으로 될 수 밖에 없다고 생각하기 때문.
- 나를 왜 뽑아야 하는지 : 팀에 기여할 수 있기 때문. 작게는 업무 프로세스 개선에서 - 크게는 코드 작성까지, 부족한 부분을 채우고
- 집념? : 원하는 거 있으면 목표를 달성할 때까지 하나만 판다. 그 과정이 조금 힘들더라도? ex) 과제할 때 2주동안 그거만 한다던가, 미어캣 프로젝트 때 프로젝트 완결 & 수상이라는 목표를 위해서 원래 맡기로 했던 역할을 넘어 팀에 기여하는 방향을 선택한다던가. (나 개인의 목표. 팀의 목표는 언제나 변할 수 있다고 생각한다.)
- 마감일 vs 퀄리티 : 퀄리티가 먼저라고 생각함. 일반적으로 마감일이라는 게 급박하게 주어지는 게 아니고, 결국 나도 처음에 동의한 내용이기 때문에 마감일을 맞추지 못하는 경우에는 삽질 등에 의해 지체되는 경우가 대부분일 것. 이 경우에, 중간중간 이러한 이유로 지체되고 있다는 것을 알리는 것이 먼저라고 생각. 프로젝트를 런칭했을 때 버그가 터져 사용자들이 불편함을 겪어 이탈하는 것과, 지연되어서 이탈하는 것을 비교하면 후자가 훨씬 나을 거라 생각. (물론 지연도 너무 많이 되면 안되겠지만)
- 일하고 싶은 도메인 : 가능하다면 트래픽을 많이 다루고, 시니어들에게 많은 것을 배울 수 있는 부서. 도메인은 음.. 이번에 네이버/네이버 클라우드/네이버랩스/네이버페이 이렇게 있는 걸로 아는데. 사용자와 가까운 도메인에 있고 싶다. 네이버나 네이버페이쪽?
- 같이 일하고 싶은 / 일하기 싫은 스타일 : 편하게 질문할 수 있는 사람. 어려움을 공유하고, 같이 고민하는 과정에서 더 빨리 문제를 해결할 수 있을 것이다. 일하기 싫은 스타일은 너무 퉁명한 경우.
- 평상시에 어떻게 공부하는지 : 기술에 대한 agenda는 유튜브 알고리즘에 뜨는 신규 기술들이나, 또는 간혹 기술 채널들에 나오는 것들을 본다. 아니면 프로그래머스 같은 데서 나오는 개발자들의 기술 통계 같은 것을 보고. 그 중에서 재밌어 보이는 것 - 내가 느꼈던 어려움을 해결할 수 있는 기술들에 대해 흥미를 가지고 공부한다. 최근에는 blue green 봤고, 이전에는 spring 이외에도 node.js, nestjs 등등 공부하기도 함.
- 꿈 : 사람들에게 긍정적인 영향을 주는 사람. 그것이 개발 내적이던, 개발 외적이던, 내가 만든 서비스를 사용하는 사람들이던 간에 나로 인해서 다른 사람들이 성장하거나, 정서적으로 편안함을 느낀다던가 등 긍정적인 영향을 주었으면 좋겠다.
- 마지막 한마디
'내가 하고싶은 것! > 취준' 카테고리의 다른 글
| Java 면접대비 질문 (0) | 2024.04.15 |
|---|---|
| Spring 면접대비 질문 (0) | 2023.10.29 |
| 자료구조 면접대비 질문 (0) | 2023.10.04 |
| 네트워크 면접대비 질문 (0) | 2023.10.04 |
| OS 면접대비 질문 (0) | 2023.10.02 |